As described in the Structure of the Enju System section of the Enju manual, Enju makes use of the universal parser up of the MAYZ toolkit. For more information on the interface of up, please look at the manual of up.
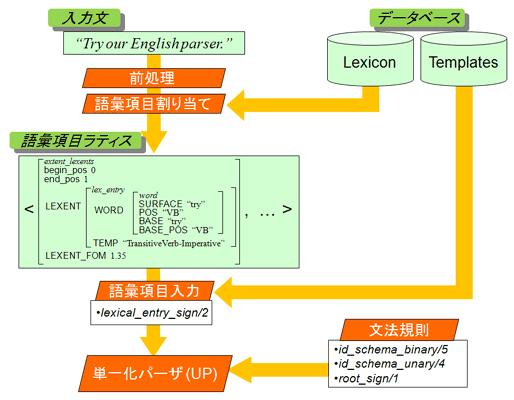
The input sentence is first passed to up and then the output of up is used for producing the final output of ENJU, as illustrated by the following diagram:
Now let me decribe each of the processes in the diagram briefly. For more details on each of the processes
The words that form the setence are tagged ann stemmedd. The input sentence is converted into a list of extents. These processes are implemented by the sentence_to_word_lattice/2 predicate.
For more details, please look at the Preprocessing section.
A dictionary and a template database are created with the MAYZ toolkit and used for creating lexicon entries. The name of a lexical entry is passed to up with the lexical_entry/2 predicate. The sign of it is passed to up with the lexical_entry_sign/2 predicate.
For more details, please look at the Dictionary and Template Database section.
HPSG rules, that is, schemata and principles, are found in "grammar/schema.lil". For more details, please look at the Schemata and Principles section.
The type of the root condition is defined by the root_sign/1 predicate in the file "grammar/grammar.lil". The instance of the type is_root_sign/1 is found in the file "grammar/macro.lil".
The probabilistic model for disambiguation is found in the file "grammar/synmodel.lil". The reading of the parameters used by the model is done here as well.
The program for calculating the probabilities is found in the file "grammar/forestprob.lil". The program for extracting features is found in the file "grammar/forestevent.lil". The mask to be applied to features is found in the file "synmask.lil". The file "grammar/synmodel.lil" would load all these models and generate data for passing to up by combining these models.
For more details, please look at the Probabilistic Model section.
The output of up is further processed into more readable forms(dependencies and XML). Dependencies are generated by "grammar/outputdep.lil". XML output is generated by "grammar/outputxml.lil".
For more details, please look at the Output section.
We can use MoriV to view the output of up and the grammar in a GUI. For more details, please look at the MoriV section.