The grammar of Enju is based on the theory of Head-driven Phrase Structure Grammar (HPSG). In HPSG, constraints on the structure of a language are represented with typed feature structures. LiLFeS Home Page presents a brief introduction to typed feature structures.
One of the characteristics of HPSG is that most of the constraints on syntax and semantics are represented in lexical entries, while only a small number of grammar rules (corresponding to CFG rules) are defined and they represent general constraints irrelevant to specific words. This is because the constraints on the structure of a sentence are mostly introduced by words.
Syntactic/semantic constraints of words/phrases are represented in the data structure called sign. In the current implementation of Enju, the structure of the sign basically follows [Pollar and Sag, 1994] and LinGO English Resource Grammar (ERG), while the type hierarchy is much simplified and modified not to use complex constraints nor Minimal Recursion Semantics (MRS).
| PHON: A sequence of words governed by the phrase | |||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Constraints of phrases include various syntactic features (part-of-speech, agreement, tense, etc.).
CONT feature has a predicate-argument structure of the phrase. Predicate-argument structures represent relations of logical subject/object and modifying relations. The CONT feature of the sign of the top node shows the predicate-argument structure of the whole sentence.
Types and features used in the Enju grammar are all defined in "enju/types.lil". For details, see the source file.
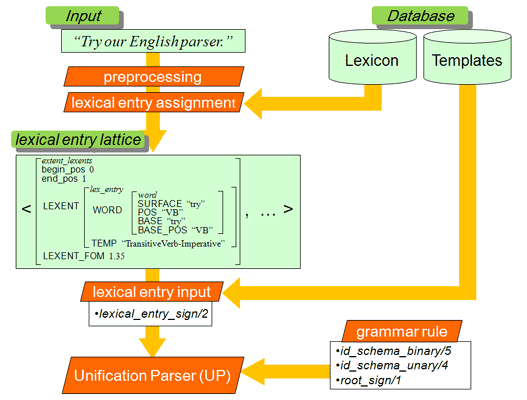
The Enju system uses UP (included in the MAYZ package), a general-purpose parser for unification grammars. UP parses a sentence with provided lexical entries and grammar rules. Enju creates the data passed to UP in the following way.
An input sentence is passed to sentence_to_word_lattice/2, and converted to a word lattice, i.e., a list of extents (a pair of word position and word information). A word lattice is passed to UP, and parsing starts. sentence_to_word_lattice/2 first applies a POS tagger to an input sentence (external_tagger/2), splits it into words, and applies stemming to the words. sentence_to_word_lattice/2 is implemented in "enju/grammar.lil". By default, a POS tagger is "uptagger", and it can be changed by "-t" option of "enju" (or by initialize_external_tagger/2).
The predicate (lexical_entry/2 and lexical_entry_sign/2) makes lexical entries by using two databases. One is a mapping from a word/POS pair into a list of the names of lexical entry templates assigned to the word (lookup_lexicon/2). The other is a mapping from the name of a template into a feature structure of the template (lookup_template/2). Lexical entries are constructed by adding word-specific information (e.g. PHON feature) to lexical entry templates. This predicate is implemented in "enju/grammar.lil".
Grammar rules (i.e., schemas) are implemented in "enju/schema.lil". They define phrase structure rules to make a mother from its daughters.
Inside UP, parsing proceeds in the following steps.
Edge is a quadruple < left-position, right-position, sign, FOM (Figure of Merit)>, which represents a phrasal structure for the sub-string of the target sentence. Left-position and right-position are positions in the sentence. Sign is a phrasal structure represented as a feature structure. That is, an edge is a phrase structures that corresponds to a region. The edge also has an information about the score (FOM) for disambiguation of analysis.
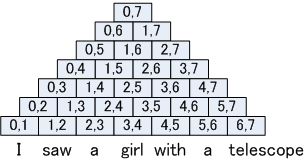
The parser has a data structure generally called `chart.' The chart is a two dimensional table. Here, we call each cell in the table `CKY cell.' Let an input sentence s(= w1, w2, w3,...,wn), for example, w1 = "I", w2="saw", w3= "a", w4 = "girl", w5 = "with", w6 = "a", w7 = "telescope" for the sentence "I saw a girl with a telescope", the chart is arranged as follows.
FOM of an edge represents how likely the edge is. When a mother edge is generated by applying a grammar rule, the FOM of the mother can be obtained by adding the score of the rule. Edges for the whole sentence region, which correspond to roots of parse trees, must satisfy the root condition. Of all the trees satisfying the condition, the one with the best FOM is taken as the final result.