Index
1. Overview
2. How To Use UP
3. Word Lattice and Extent
4. Edge
5. Chart
6. Link
7. Root Condition and Parse Tree
8. Disambiguation Module
9. Miscellaneous Items
The up is a parser that analyzes a sentence according to a unification-based grammar, e.g., HPSG. See this for further details about the grammar specifications.
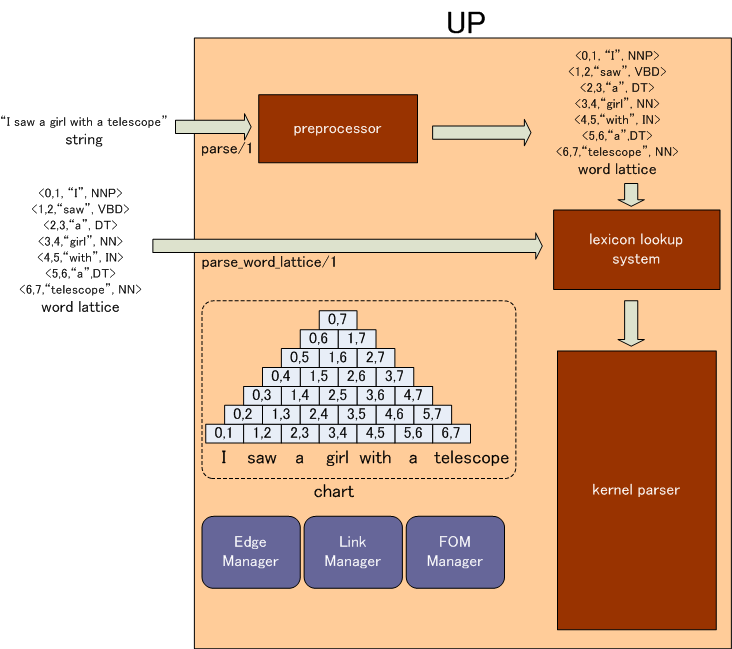
The parser starts analyzing a sentence when users call parse/1 or parse_word_lattice. Users can give the target sentence as a string or a word latttice to the parser.
| parse(+$Sentence) | |
| $Sentence | string of a sentence |
| The parser parses $Sentence. | |
| parse_word_lattice(+$WordLattice) | |
| $WordLattice | a word lattice (= a list of extent) of a sentence |
| The parser parses $WordLattice. | |
Parsing proceeds in the following steps.
As seen in the figure, the parser has data structures called chart, edge manager, link manager and FOM manager. The details of them will be explained later.
| up [options] [-a arguments] | |
| Arguments following "-a" are passed to LiLFeS programs as command-line arguments | |
| Options | |
| -L directory | Directory of LiLFeS modules |
| -W number | Limit number of words |
| -E number | Limit number of edges |
| -l module | Load LiLFeS program |
| -e command | Execute LiLFeS command |
| -i | Interactive mode (show LiLFeS prompt) |
| -n | Non-interactive mode (default) |
| -iter | With iterative beam thresholding (default) |
| -fom | With disambiguation |
| -nofom | Without disambiguation |
This tool loads LiLFeS modules specified with "-l" and executes a parser. If a lilfes command is specified, it is executed. If interactive mode is specified, it prints a command prompt of LiLFeS after executing the lilfes command.
It does nothing about loading of a lexicon and initialization of FOM models. For these, utilize the interfaces of "up" such as "parser_init".
When parse/1 is evoked, the string in the argument will be converted
to a word lattice by sentence_to_word_lattice/2, and then parse/1 does
the same process as parse_word_lattice/1 does. The word lattice is
defined as a list of extents, but the implementation of
sentence_to_word_lattice/2 must be given in the grammar. The extent
type is defined in parser.lil as follows. We call the data structure
of extent type `extent.'
extent <- [bot] + [left_position\integer(0), right_position\integer(1)].
extent_bracket <- [extent].
extent_sign_constraint <- [extent] + [sign_constraint\bot(5)].
extent_word <- [extent] + [word\bot(5)].
The children of extent type are extent_bracket,
extent_sign_constraint, extent_word, and they all have the feature
left_position\ and right_position\.
The values of left_position\ and right_position\ are integer that represents the position in the target sentence. We call the integer `position,' and the sub-string designated by the left position and the right position `region.' When the target sentence is tokenized as a sequence of words w1,w2,w3,w4,w5,...,wn, the left position of w1 is 0, and the right position is 1. In general, the left position of wi is i-1, and the right position is i. Intuitively, the relation between words and positions are illustrated as follows.
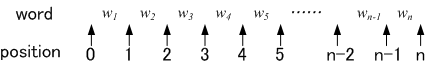
extent_word is an extent that corresponds to a word. It has not only positions, but has the values relevant to the word, e.g., the spelling, POS, in the word\ feature. The value in the word\ feature is defined in each grammar module. When the lexicon lookup process, the lexical entry is retrieved by using the value in the word\ feature.
Users can explicitly specify the phrase boundary by specifying extent_bracket. That is, the parser never generates a parse tree that cross the region specified by the extent_bracket.
Users can add constraints to the feature structures in the region by specifying extent_sign_constraint.
There is no corresponding type to edge, but edge is a quintuple < left-position, right-position, sign, a list of links, FOM >, which represents a phrasal structure for the sub-string of the target sentence. Left-position and right-position are positions in the sentence. Sign is a phrasal structure represented as a feature structure. That is, an edge is a phrase structures that corresponds to a region. The edge also has an information to reconstruct the parse tree after parsing in the list of links, and also has an information about the score (FOM) for disambiguation of analysis.
All edges are assignd IDs. The number of generated edges during paring is acquired by calling get_edge_number/1. The positions of an edge is acquired by calling edge_position/3, and the sign of an edge is acquired by calling edge_sign/2, specifying the ID of the edge.
| get_edge_number(-$Num) | |
| $Num | the number of edges |
| This retures the number of all edges generated during parsing. It is valid until the next sentence is input. ID of each edge is an integer from 0 to $Num -1. | |
| edge_sign(+$ID, -$Sign) | |
| $ID | The ID of an edge: integer |
| $Sign | sign |
| This returns a sign of the edge identified by the edge ID $ID. | |
| edge_position(+$ID, -$Left, -$Right) | |
| $ID | The ID of an edge: integer |
| $Left | left position |
| $Right | right position |
| This returns the left and right postion of the edge ideintified by the edge ID $ID. | |
The parser has a data structure generally called `chart.' The chart is a two dimensional table. Here, we call each cell in the table `CKY cell.' Let an input sentence s(= w1, w2, w3,...,wn), for example, w1 = "I", w2="saw", w3= "a", w4 = "girl", w5 = "with", w6 = "a", w7 = "telescope" for the sentence "I saw a girl with a telescope", the chart is arranged as follows.
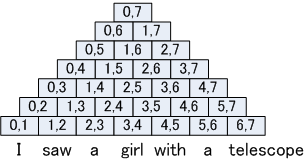
The edges on the chart can be acquired by calling edge_id_list/3 and top_edge_id_list/1.
| edge_id_list(+$Left, +$Right, -$IDList) | |
| $Left | the left postion of the CKY cell |
| $Right | the right postion of the CKY cell |
| $IDList | Edge ID list |
| This returns all edges stored in S[$Left][$Right]. | |
| top_edge_id_list(-$IDList) | |
| $IDList | Edge ID list |
| This returns all edges store in S[0][n] where n is the sentence length. | |
During parsing, an edge (parent) is generated by applying the grammar rules to two edges (children). For example, the results of applying the grammar rules to an edge in S[0][3] and an edge in S[3][5] are stored to S[0][5]. When an edge is store to a CKY cell, signs are reduced, and if reduced signs are equivalent with any of reduced signs in the same CKY cell, reduced signs are packed into one sign. This process is called `factoring.' The information that are cut off during factoring is stored to another data structure called `link.' For example, the signs of children in the parent are cut off in Enju. Instead, the IDs of child edges are stored as links in the parent's edge. Because several reduced signs are packed into one, the edge has several links.
A link is represented as the link type defined in parser.lil as follows.
link <- [bot] + [SIGN_PLUS\bot (-100)].
terminal <- [link] + [LEX_NAME\bot (5)].
nonterminal <- [link] + [APPLIED_SCHEMA\bot (5)].
nonterminal_binary <- [nonterminal] + [L_DTR\integer(0), R_DTR\integer(1)].
nonterminal_unary <- [nonterminal] + [U_DTR\integer(0)].
terminal is a link that corresponds to a lexical entry.
nonterminal_binary is a link that corresponds to a phrasal sign
generated by a binary grammar rules. nonterminal_unairy is a link
that corresponds to a phrasal sign generated by a unary grammar rule.
The value of APPLIED_SCHEMA\ is an ID of the grammar rule used for
generating the link. The value of SIGN_PLUS\ is a feature structure
that is cut off during factoring. Namely, the original sign is
restored by unifying reduced sign and the value in SIGN_PLUS\. The
value of L_DTR\ is an edge ID of the left child, and the value of
R_DTR\ is an edge ID of the right child. The value of U_DTR\ is an
edge ID of the child for the construction by unary grammar rules.
The link of an edge can be retriebed by calling edge_link_id_list/2 and edge_link/2.
| edge_link_id_list($ID, $LinkIDs) | |
| $ID | an edge ID |
| $LinkIDs | a list of link IDs |
| This returns a list of link IDs that the edge of $ID has. | |
| edge_link($ID, $Link) | |
| $ID | a link ID |
| $Link | a link |
| This returns the link corresponding to the link ID $ID. | |
All edges that contributes to the final result of parsing must satisfy the root condition of parse trees. It can be verified by calling root_sign/1 explained in How to use a grammar. root_edge_id_list returns only edge IDs which satisfy the root condition.
| root_edge_id_list(-$IDList) | |
| $IDList | a list of edge IDs |
| This returns a list of edge IDs which satisfy the root condition and in S[0][n] where n is the sentence length. | |
get_parse_tree/2 reconstruct a parse tree by following edge and link informations.
| get_parse_tree(+$ID, -$Tree) | |
| $ID | an edge ID |
| $Tree | a parse tree |
| This returns a parse tree such that the root sign of the parse tree is specified by the edge ID $ID. All parse trees can be retrieved by backtracking. | |
If the disambiguation module is supported in the grammar, the score of each edge can be retrieved by calling edge_fom/2. We call the score FOM (Figure of Merit).
| edge_fom(+$ID, -$FOM) | |
| $ID | an edge ID |
| $FOM | FOM |
| This returns the FOM of the edge specified by the edge ID $ID. | |
| edge_link_fom(+$ID, -$FOM) | |
| $ID | a link ID |
| $FOM | FOM |
| This returns the FOM of the link specified by the link ID $ID. | |
| best_fom_sign(-$ID, -$Sign, -$FOM) | |
| $ID | an edge ID |
| $Sign | sign |
| $FOM | FOM |
| This returns the ID, sign and FOM of an edge of the best FOM. | |
| best_fom_tree(-$Tree, -$FOM) | |
| $Tree | a parse tree |
| $FOM | FOM |
| This returns the parse tree of the best FOM. | |
| parser_init | |
| parser_term | |
| This is automatically called from the parser when the parser finish its initialization or termination. It is useful for the grammar writer to specify the maximum length of sentence, maximum size of edges, quick check path, etc. |
| get_limit_sentence_length(-$Len) | |
| set_limit_sentence_length(+$Len) | |
| $Len | the maximum length of sentences |
| This retrieves/sets the maximum length of sentences. If a sentence longer than this number is input, then the parser fails with the parsing state `parse_error_too_long.' | |
| get_limit_edge_number(-$Num) | |
| set_limit_edge_number(+$Num) | |
| $Num | the maximum number of edges |
| This retrieves/sets the maximum number of edges. If edges are generated more than this number, then the parser fails with the parsing state `parse_error_edge_limit.' | |
| set_parser_mode(+$Name, +$Val) | |
| get_parser_mode(+$Name, +$Val) | |
| $Name | parser mode name |
| $Val | parser mode value |
| This retrieves/sets the parse mode. Currently, users can specify "quick check path" and "enable quick check" only. | |
| set_beam_thresholding_params($Num, $Width) | |
| $Num | the maximum number of edges in each CKY cell |
| $Width | the beam threshold |
| When beam search is evoked, edges in each CKY is sorted according to their FOM, at most $Num edges remains in each CKY cell, and only edges that has FOM greater than the highest FOM in the CKY cell minus the beam threshold $Width. | |
| get_parse_status($Status) | |
| $Status | the status of the parser. Currently, there five types of parser status; mayz:parser:parse_success, mayz:parser:preproc_error, mayz:parser:parse_error_too_long, mayz:parser:parse_error_edge_limit, mayz:parser:parse_error_unknown |
| This returns the status of the parser. parse_success means that the parsing succeeded. preproc_error means that an error occured during preprocessing. parse_error_too_long means that the input sentence is too long, i.e., that is longer than the maximum sentence length. parse_error_edge_limit means that the parser failed parsing because the number of generated edges is greater than the maximum edge number specified by set_limit_edge_number/1. | |
| get_sentence($Sentence) | |
| get_word_lattice($WordLattice) | |
| $Sentence | a sentence |
| $WordLattice | a word lattice (= a list of extents) |
| This returns the input sentence or the word lattice. This is valid until the next sentence is input. | |
| get_sentence_length($Len) | |
| $Len | the sentence length |
| This returns the sentence length. This is valid until the next sentence is input. | |
| get_analyze_word_time($Time) | |
| get_analyze_lexent_time($Time) | |
| get_analyze_parse_time($Time) | |
| get_parse_setup_time($Time) | |
| get_parse_lex_time($Time) | |
| get_parse_phrase_time($Time) | |
| get_total_time($Time) | |
| $Time | time (msec) |
| get_analyze_word_time, get_analyze_lexent_time and get_analyze_parse_time return word analysis time, lexical-entry analysis time, parsing time respevtively. get_total_time is a sum of these get_analyze_* time. get_parse_setup_time, get_parse_lex_time and get_parse_phrase_time return setup time, leaf analysis time and phrase analysis time during parsing. That is, the sum of get_parse_* is less than get_analyze_parse_time. These are valid until next sentence is input. | |
| get_parser_name($Name) | |
| get_parser_version($Version) | |
| $Name | the parser's name |
| $Version | the parser's version |
| These return the parser's name and the parser's version respectively. | |
| get_grammar_name(-$Name) | |
| get_grammar_version(-$Version) | |
| set_grammar_name(+$Name) | |
| set_grammar_version(+$Version) | |
| $Name | the grammar's name |
| $Version | the grammar's version |
| These retrieve/set the grammar name/version. This is optional. | |