In this section, we would take the sentence "I saw a girl with a telescope." as an example to illustrate how parsing is done by EnjuÅD
As described in the Preprocessing section, preprocessing is handled by the sentence_to_word_lattice/2 predicateÅD
The input sentences is first tagged by the external_tagger/2 predicateÅD
"I/PRP saw/VBD a/DT girl/NN with/IN a/DT telescope/NN ./."The tagged sentence is then processed into a list of Word/POS pairs and stemmed. Next, feature structures of the 'extent_word' type is created by the token_to_word_lattice/2 predicate for each word. Below is the representation of "saw" as a feature structure of the 'extent_word' type.
| extent_word | ||||||||||||||||||||
| left_pos | 1 | |||||||||||||||||||
| right_pos | 2 | |||||||||||||||||||
| word | < |
| > | |||||||||||||||||
We use the predicates lexical_entry/2 and lexical_entry_sign/2 for passing the signs of lexical entries to up.
The lexical_entry/2 predicate is called by the value of the word feature of a feature structure of the 'extent_word' type. The value assigned to this feature is a list of 'word'. lookup_lexicon/2 would look for the template for each element of the list. The subclauseslexicon_lookup_key and unknown_word_lookup_key/2 of lookup_lexicon/2would come up with keys for retrieving lexical entries from the dictionary. For the feature structure corresponding to "saw", the value of the word feature is a one-item list. The key corresponding to this item created by lexicon_lookup_key/2 is made up by the based form and the POS of the input word. The key for "saw" is given as follows:
| word | |||
| BASE | "see" | ||
| POS | "VBD" |
| lex_template | |||
| LEXEME_NAME | "[npVPnp]xm_10" | ||
| LEXICAL_RULES | <past_verb_rule> | ||
| lex_entry | ||||||||||||||||||
| LEX_WORD |
|
|||||||||||||||||
| LEX_TEMPLATE |
|
|||||||||||||||||
Next, the lexical_entry_sign/2 predicate is called for each of the remaining feature structure of the 'lex_entry' type. Under the lexical_entry_sign/2 predicate, a lookup_template/2 predicate is defined for looking up the dictionary using the value of the LEX_TEMPLATE feature of a feature structure of the 'lex_entry' type. For the feature structure of the lex_entry type given immediately before this paragraph, we would obtain a template like this. Information that varies from lexical entries would be added to the template. In addition, the value of the LEX_WORD\INPUT feature would unify with the value of the PHON feature. ÅD The resultof these operations would be the output of the lexical_entry_sign/2 predicate.
The output is a feature structure of the sign type. It is supplied to the reduce_sign/3 predicate for factoringÅDFactoring is the operation of removing information from a feature structure of the sign type. Instances of equivalent signs are contracted into a single sign. The contracted sign is used for any parsing to be done in future. Supplying a sign to the reduce_sign/3 would return a contracted sign and the information removed from the sign. ÅD(For more details, please look at the linksection.) After that, supplying with the fom_terminal/4 predicate a feature structure of 'lex_entry' type, a contracted sign corresponding to the same feature structure and prunned information during contraction returns a FOM score. At this point, sign with low FOM scores are prunned as well.
UP makes use of data structures generally referred to as edges, charts and links for parsing.
An edge is made up by a left position, a right position, a sign, a list of links and a FOM score. The left position and the right position is for marking the position of a parsed fragment. In short, an edge is essentially the representation of the sign corresponding to a fragment starting from the left position and ending at the right position. The extra information are the information stored as a list of links for recovering prunned information and a FOM score for disambiguation.
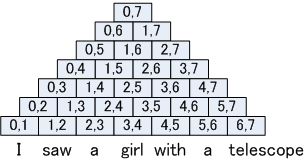
A chart is a data structure used for preserving the state of a parse. We use a 2-D table to represent such a chart. Each element in the chart is referred to as a CKY cell. For the sentence "I saw a girl with a telescope", the chart constructed at the point parsing starts is as follows:ÅD
When parsing proceeds, syntactic rules defined by id_schema_unary/4 and id_schema_binary/5would be applied to child nodes for forming mother nodes. For example, the result of applying syntactic rules on edges stored in S[1][2] and S[2][4] would be stored in S[1][4]ÅDAt this point, signs that are equivalent and stored in the same CKY cell would be contracted into one sign as a result of the factoring operation defined by the reduce_sign/3 predicate. Factoring removes information that can be recovered after parsing finishes. In order to allow such recovery, data structures referred to as links are created for enabling such recovery. Information removed by factoring includes the signs of child nodes and semantic representations. This kind of information are stored as links. Given that edges resulted from contraction are formed with more than one edges. one such edge would correspond to multiple links. After parsing finishes, the whole parse tree can be traced through the links between edges.
For the example sentence "I saw a girl with a telescope.", among the edges stored in S[1][2] is one edge that contains a sign that looks like this and among the edges stored in S[2][4] is another edge that contains another sign that looks like thisÅDThe 'head_comp_schema' specified by theid_schema_binary/5 predicate is then applied to these two signsÅD The arguments of the id_schema_binary/5 predicate are the name of the schema to be applied, the feature structure of the left daughter, the feature structure of the right daughter, the feature structure of the mother node and the lilfes program to be executed after applying the specified schema. (The id_schema_unary/4 predicate has only one feature structure for daughter nodes.) The feature structures of the left daughter and the right daughter of the 'head_comp_schema' are roughly as follows:
| , |
|
| ||||||||||
|
So parsing proceeds until we come to the CKY cell corresponding to the whole sentence (In this case, it is S[0][7]). A FOM score would be calculated for each of the edge in this cell by the fom_root/2 predicate. Supplying the sign of a root node to fom_root/2 would return the FOM score of that sign. Whether these edges satisfy the root condition would be determined by the root_sign/1 predicate. For the example sentence "I saw a girl with a telescope.", there is a sign like this in S[0][7] which gets the highest FOM among all edges that satisfy the root condition. This sign is the result of contracting two signs into one, one of which corresponding to the analysis that attaches "with a telescope" to the VP, the other corresponding to the analysis that attaches "with a telescope" to the NP. By tracing through the edges and the links, following the path with the best FOM score, we can recover the sign with the best FOM score.
The sign with the highest FOM score obtained from the above parse would be outputed. For the above example, the output from the "enju/outputdeps.lil" module would be as follows:
ROOT ROOT ROOT ROOT -1 ROOT saw see VBD VB 1 saw see VBD VB 1 ARG1 I i PRP PRP 0 saw see VBD VB 1 ARG2 girl girl NN NN 3 a a DT DT 2 ARG1 girl girl NN NN 3 a a DT DT 5 ARG1 telescope telescope NN NN 6 with with IN IN 4 ARG1 saw see VBD VB 1 with with IN IN 4 ARG2 telescope telescope NN NN 6